|
Email Filtering for Nonprofits Panel Presentation at 2003 N-TEN Roundup Emerging Technologies Session Brent Emerson | brent@electricembers.net http://electricembers.net/pubs/filtering/ Email filtering: what can we filter? Hopefully, we can filter or will develop means to filter out anything an organization or a user doesn't want to receive. Usually, these messages fall into three general categories: viruses (malicious code), spam (bulk, automated, or commercial unsolicited email), and abuse (targeted offensive or abusive messages). Email has become a crucial tool of communication, and anything which reduces its effectiveness reduces the effectiveness of our organizations. This is especially true in the nonprofit sector, where we may be dealing with more email communication relative to our reduced human resources than many for-profit entities. And the problem is becoming more intense and complicated lately in that these three categories, while still very useful, are starting to blur. It's becoming more and more difficult to draw the distinctions, as viral, spammy and abusive characteristics are increasingly found together. Examples of this blurring: viruslike spam - spam so rampant and irritating that it is seen as an infection affecting the functioning of the email system; spamlike viruses - "ad-ware" and other code which doesn't cause damage but just advertises and annoys; abuselike spam - spam that is offensive to users; and spamlike abuse - automated bulk targeted harassment. The problem of email viruses, spam and abuse may be developing into one problem rather than three, and the future may see it coalesce further. So our approach will need to respond to this blurring - an active response with a coordinated strategy is becoming more and more relevant. I'll focus here primarily on anti-spam (AS) filtering technology since
there's less "emerging technology" in the anti-virus (AV) world and
anti-abuse filtering is mostly a subset of AS. But first a few notes on
virus filtering.
Why filter viruses in email?At first glance, it's clear that viruses are annoying and destructive and we want to get rid of them any way we can. But why bother with the extra expense of removing viruses from email?
New developments in AVVirus scanning and disinfection in general hasn't changed much lately, except that over the last several years more and more viruses are actually email worms, so antiviral email filtering has become more useful. A plethora of commercially available mature server-side filtering solutions and discounts on client AV software (as in Compumentor's DiscountTech program) means AV shouldn't be a big challenge for nonprofits. One big change that I'm excited about is the rise of open source / free
antivirus software. AV is an area where open-source hasn't yet
penetrated, probably because of the need to keep virus pattern databases
up to date if software is to be successful. ClamAV and OpenAntiVirus are
newly-developed examples of open-source virus scanning engines, as opposed
to open-source tools that use commercial engines or pattern databases.
There is conflicting anecdotal evidence about their effectiveness and not
a lot of conclusive evidence -- they need more adopters and more
widespread testing before it's clear if they're as effective as commercial
products.
Why filter spam?Opinions are divided about how big a problem spam is: some organizations don't get much, some get a lot. The impact is often divided even within an organization, as maintainers of public addresses (like an info@ account) wade through spam all day and others with more private addresses aren't aware of it at all. An organization's response is mostly based on how many public addresses they have and on the traffic patterns of their users, which mirrors the internet-wide divide between hotmail accounts which receive 100 spams per day and new accounts in small domains that don't get spam for their first year. In addition, definitions of spam vary - it can be hard to pin down a universally accepted definition. (For more on this issue, see the recent forum Spammers and Scammers on techsoup.com, especially the thread on Spam v. Internet Activism.) But if we were to plow through 1000 candidate spam messages here as a group today, I imagine we'd agree on at least 90% of it. And one thing is certain: spam traffic is growing. Spam volume is increasing Internet-wide and it's increasing by account as each account ages and is ever more exposed to the world. As long as the cost of sending spam is lower than the cost of rejecting it, it will continue to be a problem, becoming more major and widespread. So we have two connected goals: increase the cost and difficulty of sending spam effectively and decrease the cost and difficulty of not receiving spam you're sent. The old way: Centralized DNS BlacklistsThe use of centralized DNS blacklists to block spam is the technique most people think of when I mention AS filtering, which makes sense as it's the oldest and most well-known. Blacklists are databases of IP addresses of open SMTP relays or other machines frequently used by spammers - users block all mail coming from these addresses to preemptively block spam. Unfortunately, this technique doesn't work to block more than a small percentage of spam. It was very successful compared to nothing, when spam was new, but seems like a failure against today's spam problem. Because spammers can jump from IP to IP, a filtering strategy that pays attention only to the network routing information in a message is doomed to mediocrity at best. To distinguish spam effectively, a machine needs to identify it the same way we do: by inspecting its content. The new way: A wide-spectrum approachA new way to identify and handle spam is taking hold - instead of blocking incoming mail based on where it's coming from (which often results in false positives that mean users never receive legitimate email), messages are tested against a variety of different conditions. If they meet enough conditions to be considered spam, the message can be deleted. Better yet, it can be marked and delivered normally so that the recipient can decide how to handle it. So even if there are false positives, users never lose any mail. Here are the four main message test techniques: IP-BASED TESTScentralized/authoritative: DNS-queried blacklist databases of IP addresses of open SMTP relays, machines frequently used by spammers, dynamic dialup lines, whitelist warrant abusers, and other high-spam-risk IP addresses can be used to reject or identify suspect mail. distributed/trust-based: Like centralized blacklists, only these are maintained by the community that uses them instead of an external authority. Community members and their contributions are trusted and admitted to the system based on their agreement with other trusted members' contributions. self-administered: Firewalls (for IP or SMTP), MTA access rules (for SMTP) or custom IP address checks in an AS scanner can be used to block or identify traffic that one has independently determined to be undesirable based on individual experience. PATTERN MATCHINGheader patterns: A text processor can scan through message headers looking for addresses, address patterns or header irregularities that are often found in spam, or whitelisted addresses or whitelist warrants that are not often found in spam. body patterns: A text processor can scan through message bodies (the content most users see) looking for text, formatting and stylistic characteristics that are often found in spam or not often found in spam. DISTRIBUTED WHOLE-MESSAGE CHECKSUMSCommunity-contributed hashes of entire spam messages are stored in a database on a central server. When an MTA receives a message, it can query the server to determine whether the message has been previously reported as spam. Since these systems rely on an actual human being judging a specific message to be spam, they can be very effective. Because these systems rely on contributions from a widespread community, they become more and more effective as more and more people use them. STATISTICAL COMPARISONS TO KNOWN GOOD/BAD EMAILIn August 2002, a programmer named Paul Graham proposed using statistical analysis of a user's old messages to judge the probability that a new message was spam. He fed the algorithm with a large body of non-spam email he had received and a large body of spam he had received to teach it how often different words occurred in each. His algorithm, a variant of the Naive Bayesian algorithm, could then estimate the probability that a message was spam or non-spam given that it contained a certain word, by comparing it to the kinds of messages he ordinariy received. When the analysis is extended to all the words in a message (or even just the fifteen most clear-cut), the estimate is strikingly accurate. It wasn't actually a new idea, but Graham's results were impressive (he reports that his implementation correctly distinguished over 99% of the next 1000 spams he received with no false positives) and the idea caught on quickly. His algorithm and similar statistical analyses are now being implemented and experimented with on a variety of platforms. Why is wide-spectrum better?Opinions differ about how appropriate or promising each of these techniques is, and some people prefer to use just one. But there are several very good reasons to use a variety of techniques:
And indeed, the wide-spectrum approach has proven very effective:
SpamAssassin (currently using three of the four technique-families) claims
to differentiate between spam and non-spam in 95-99% of cases. In my own
experience I've seen these tools detect 90-95% of spam, with nearly zero
false positives, and then only on spamlike messages.
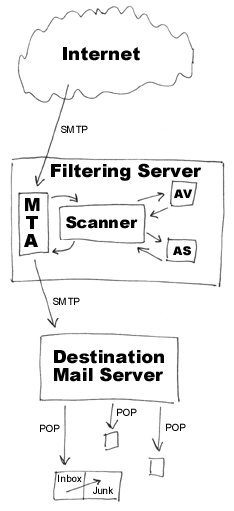
Here I'll quickly describe a prototype email filtering server resembling the setup at NPOshield, the email filtering service I've built over the past year:
At NPOshield I use Sendmail as the MTA, MailScanner as the mail
scanner, Clam AntiVirus as the AV engine, and SpamAssassin as the AS
engine. Some sample (extra-verbose) output from SpamAssassin can be seen
in the accompanying materials for this presentation, showing positive
tests and how the message was scored. Interesting things to note: all
three methods were used to score the spam (IP check, header/body patterns,
whole-message report); although the tests all have low individual scores,
the combined score is far above the threshold; and the X-Spam-Level header
allows advanced users to filter spam on their own threshold instead of the
centrally defined one if they prefer.
Do you need to filter?Are the reasons to filter against viruses (added protection, reduction in unnecessary network traffic) important enough to justify the costs? Are the reasons to filter against spam (reduction in staff irritation, increased email productivity, reduction in unnecessary network traffic / disk storage) important enough to justify the costs? Are there privacy issues within your organization that would make it inappropriate or controversial to have a machine scanning email content?DIY v. ASPIf you decide to filter, you'll need to decide between installing and maintaining a do-it-yourself (DIY) software product (running either on your mail server or your mail clients) or a server-based scanning service hosted at an ASP. Some advantages/disadvantages of different solutions and questions to consider:
Comparing specific AV/AS solutionsAV CRITERIA
AS CRITERIA
| ||||||||||||||||||